概要
前回は grape を使って RESTful API を構築してみました
grape には grape-swagger がありこれを使うと swagger のドキュメントを自動生成してくれます
今回は導入方法と使い方のポイントを紹介します
また説明は前回のアプリをそのまま使います
環境
- macOS 10.15.6
- Ruby 2.7.1p83
- grape 1.4.0
- grape-swagger 1.3.0
とりあえず使ってみる
既存の grape アプリがあれば簡単に導入できます
まずは gem を追加しましょう
gem "grape"
gem "grape-swagger"
そしてアプリに add_swagger_documentation を追加するだけです
require 'grape'
require 'grape-swagger'
module Test
class API < Grape::API
format :json
prefix :api
articles = []
@username = ""
resource :blog do
desc 'Return an article.'
get :article do
articles
end
desc 'Create new article.'
params do
requires :title, type: String, desc: 'An article title'
requires :body, type: String, desc: 'An article body'
end
post do
articles.append({
title: params[:title],
body: params[:body]
})
end
desc 'Delete an article.'
params do
requires :index, type: Integer, desc: 'An article index'
end
delete ':index' do
error!("Does not found index", 404) if articles[params[:index]].nil?
articles.delete_at(params[:index])
end
desc 'Update an article.'
params do
requires :index, type: Integer, desc: 'An article index'
requires :title, type: String, desc: 'An article title'
requires :body, type: String, desc: 'An article body'
end
put ':index' do
error!("Does not found index", 404) if articles[params[:index]].nil?
articles[params[:index]] = {
title: params[:title],
body: params[:body]
}
end
end
add_swagger_documentation
end
end
あとは普通にアプリを起動しましょう
bundle exec rackup config.ru
すると localhost:9292/api/swagger_doc にアクセスするだけで swagger の JSON が返っくることが確認できると思います
CORS に対応する
SwaggerUI を使って確認する場合に CORS に対応しておかないと JSON にアクセスできません
わざわざファイルに落として読み込ませるのも面倒なので CORS に対応しておきます
gem "rack-cors"
gem "grape"
gem "grape-swagger"
require 'rack/cors'
use Rack::Cors do
allow do
origins '*'
resource '*', headers: :any, methods: [ :get, :post, :put, :delete, :options ]
end
end
require './app'
Test::API.compile!
run Test::API
これで SwaggerUI から確認してみましょう
SwaggerUI から確認してみる
grape-swagger は単純に swagger 定義の JSON を出力してくれるだけで SwaggerUI の機能はありません
なので確認する場合は別途 SwaggerUI を使いましょう
docker run -d -p 8080:8080 swaggerapi/swagger-ui
あとは localhost:8080 にアクセスして grape-swagger で出力される JSON の URL を入力すれば OK です
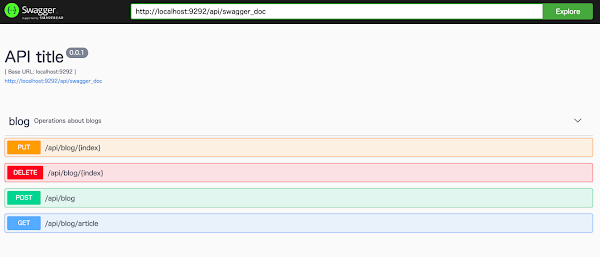
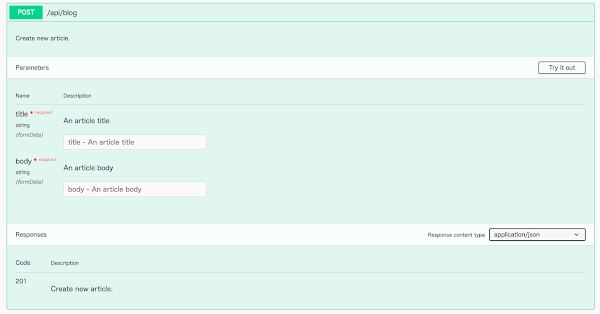
こんな感じで API の定義を確認することができます
レスポンスのサンプルを追加してみる
このままでも十分といえば十分ですがレスポンスにボディがある場合にそれを表示することができません
そんな場合は grape-entity を使います
gem "rack-cors"
gem "grape"
gem "grape-swagger"
gem "grape-entity"
gem "grape-swagger-entity"
まずは Entity を追加します
必ず Grape::Entity クラスを継承して作成します
expose を使うことでフィールドとして登録することができます
require 'grape'
require 'grape-swagger'
require 'grape-entity'
require 'grape-swagger-entity'
module Test
module Entities
class Article < Grape::Entity
expose :title, documentation: { type: 'string', desc: 'Blog article title.', required: true }
expose :body, documentation: { type: 'string', desc: 'Blog article body', required: true }
end
end
end
次に定義した Entity を登録します
これも簡単で既存の grape アプリで定義した desc の引数に entity: ハッシュとして追加するだけです
desc 'Create new article.',
entity: Test::Entities::Article
params do
requires :title, type: String, desc: 'An article title'
requires :body, type: String, desc: 'An article body'
end
post do
articles.append({
title: params[:title],
body: params[:body]
})
end
これで OK です
あとはアプリを起動して localhost:9292/api/swagger_doc を確認するとちゃんとレスポンスサンプルとして含まれていることが確認できると思います
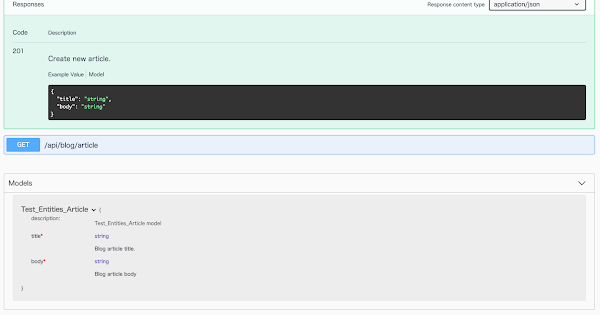
パラメータとしても使える
既存の grape アプリの params の代替にもなります
desc の引数のハッシュに params: として追加するだけで OK です
desc 'Create new article.',
entity: Test::Entities::Article,
params: Test::Entities::Article.documentation
post do
articles.append({
title: params[:title],
body: params[:body]
})
end
こちらのほうが管理的にもきれいになるので良いかなと思います
全体のソースコード
一応紹介しておきます
require 'grape'
require 'grape-swagger'
require 'grape-entity'
require 'grape-swagger-entity'
module Test
module Entities
class Article < Grape::Entity
expose :title, documentation: { type: 'string', desc: 'Blog article title.', required: true }
expose :body, documentation: { type: 'string', desc: 'Blog article body', required: true }
end
end
class API < Grape::API
format :json
prefix :api
articles = []
@username = ""
resource :blog do
desc 'Return an article.'
get :article do
articles
end
desc 'Create new article.',
entity: Test::Entities::Article,
params: Test::Entities::Article.documentation
post do
articles.append({
title: params[:title],
body: params[:body]
})
end
desc 'Delete an article.'
params do
requires :index, type: Integer, desc: 'An article index'
end
delete ':index' do
error!("Does not found index", 404) if articles[params[:index]].nil?
articles.delete_at(params[:index])
end
desc 'Update an article.'
params do
requires :index, type: Integer, desc: 'An article index'
requires :title, type: String, desc: 'An article title'
requires :body, type: String, desc: 'An article body'
end
put ':index' do
error!("Does not found index", 404) if articles[params[:index]].nil?
articles[params[:index]] = {
title: params[:title],
body: params[:body]
}
end
end
add_swagger_documentation
end
end
require 'rack/cors'
use Rack::Cors do
allow do
origins '*'
resource '*', headers: :any, methods: [ :get, :post, :put, :delete, :options ]
end
end
require './app'
Test::API.compile!
run Test::API
source "https://rubygems.org"
git_source(:github) {|repo_name| "https://github.com/#{repo_name}" }
gem "rack-cors"
gem "grape"
gem "grape-swagger"
gem "grape-entity"
gem "grape-swagger-entity"
最後に
grape-swagger を使って grape のアプリから swagger のドキュメントを自動生成する方法を紹介しました
手動で swagger ファイルを書くよりかは重複を避けられたり管理が楽になので良いかなと思います
定義した Entity をレスポンスのサンプルにしたり実際に API で扱うパラメータにする方法も紹介しました
今回は調査しなかったのですが作成した Entity をデータベースのモデルにしてオブジェクトを生成しフィールドにアクセスすることができれば更に便利な使い方ができるかなと思います
参考サイト













